

Inhaltsübersicht
Die Informationslandschaft im Internet wird von einigen wenigen kommerziellen Suchmaschinen-Betreibern dominiert, allen voran Google. Der Erfolg der Suchmaschinen in technologischer Hinsicht, aber auch aus der Sicht der Usability, hat großen Einfluss auf das Nutzerverhalten. Damit wurde ein Standard etabliert, an dem sich heutige und zukünftige Informations-Systeme orientieren (müssen). NutzerInnen haben bestimmte Designpatterns erlernt und übertragen diese in Form von Erwartungen auf andere gleichartige Anwendungen.
Die intuitive Handhabung von Suchmaschinen basiert auf einem simplen Design der Benutzeroberfläche (User Interface). Der einfache Suchschlitz hat sich zu einem Standard etabliert: ein Eingabefeld für alle Benutzereingaben. Die Implementierungen von Suchfunktionen auf „gewöhnlichen“ Webseiten oder auch auf großen Portalseiten folgen überwiegend jenem Paradigma, das durch Web-Suchmaschinen populär wurde.
Die naturgemäße Herausforderung dabei ist, zu erschließen, wonach der Nutzer eigentlich sucht. Eingaben sind durchschnittlich recht knapp gehalten (einige wenige Wörter) und oft auch vage (ungenaue Schreibweise). Die Anfragen der NutzerInnen in relevante Vorschläge zu Quellen und Dokumenten zu verwandeln ist die Hauptleistung der Suchmaschine und wird als Interpretationsleistung der Suchmaschine bezeichnet. Das geschieht mittels komplexer Algorythmen und intelligenter Indizierung der Quellinformationen.
Eine Anfrage führt häufig zu sehr großen Trefferzahlen, die nachträglich stärker eingeschränkt und aufbereitet werden müssen. Wiefolgt werden einige Design-Standards besprochen, die bei der Recherche nach relevanten Quellen im Internet oder innnerhalb eines digitalen Datenbestandes intuitiv unterstützen.
Facettierte Suche
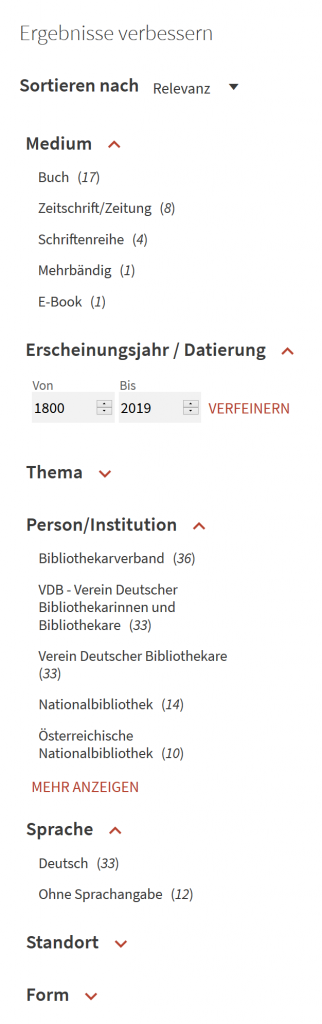
Eine sehr praktische Funktionalität ist ebenfalls zu einem Standard in der Recherche geworden: die facettierte Suche bzw. Drill-Down-Menüs. Die facettierte Suche ermöglicht eine nachträgliche weitere Verfeinerung oder Verbesserung des Suchergebnisses über entsprechende Vorschläge, die sich aus den Daten selbst ergeben. Ein an der Universitätsbibliothek Leipzig durchgeführter Usability-Test ergab, dass das Arbeiten mit den Facetten intuitiv und einfach ist. (siehe Berges, Vanessa. „Die Usability suchmaschinenbasierter Bibliothekskataloge.“ In Wiborada online – Leipziger Schriften zur Bibliotheks- und Informationswissenschaft. Hrsg. von Andrea Nikolaizig. 4–15. Leipzig: Hochschule für Technik, Wirtschaft und Kultur Leipzig, 2013: 65)
(Foto: www.onb.ac.at)
Die Daten zur weiteren Eingrenzung stammen aus Aggregationen über die jeweiligen Datenfelder (z.B.: Autor, Erscheinungsjahr, Stichwort, Medienart, Sprache) – oder anders ausgedrückt: es sind Gruppierungen nach Feldtyp.
Als einfache SQL-Anweisung könnte dies so aussehen:
SELECT COUNT(languageID), language FROM books WHERE title LIKE '%Antarktis%'
GROUP BY language
ORDER BY COUNT(languageID) DESC;
Diese Anweisung liefert die Anzahl aller verfügbaren Sprachen jener Dokumente, in denen der Suchbegriff „Antarktis“ im Titel an beliebiger Stelle vorkommt. Eine Suchanfrage beinhaltet allerdings mehrere Aggregationen, die dann für diese Menüs genutzt werden können, weshalb diese naturbedingt auch als performanceintensive Operationen gelten. Die Suchmaschine bzw. NoSQL-Datenbanken im Allgemeinen sind für diese Anforderung am besten gerüstet. Das ist auch der Grund warum in diesem Anwendungsszenario auf NoSQL-Technologie gesetzt wird – also auf nichtrelationale Datenbanksysteme. Dokumente sind nach diesem Ansatz denormalisiert, um das Laufzeitverhalten zu verbessern. (Die Daten sind daher auch nicht mehr redundanzfrei.)
Autovervollständigung
Für die Performance einer Suche wichtig ist die Funktionalität Autovervollständigung oder Seach-as-you-type. Diese Eingabehilfe ist bei der Suche kaum mehr wegzudenken, denn sie löst gleich mehrere Herausforderungen auf einmal. Eine Grundannahme sei an dieser Stelle vorausgesetzt: ein Benutzer kennt weder die Datenstruktur noch weiß er um den Umfang der Datensammlung Bescheid; er kennt das standardisierte Vokabular nicht. Bei einer thematischen Suche ist die genaue Schreibweise des gesuchten Datenmaterials meist ebenfalls nicht bekannt. Die Autovervollständigung ist ein guter erster Einstiegspunkt, um schnell zu relevanten Ergebnissen zu kommen.
Am Beispiel folgender Suchbegriffe soll dies veranschaulicht werden: kleine naturwissenschaftliche
Für die Umsetzung benötigen wir ein klares Verständnis unseres Use-Cases: Als Benutzer beginne ich mit der Eingabe von mindestens zwei Zeichen und die Suchmaschine vervollständigt diese mittels Treffer aus dem Index der Autovervollständigung, wobei die Vorschläge mit den eingegebenen Zeichen beginnen müssen und das gesamte Zitat beinhalten.
Eingabe (Prefix/beginnt mit): kleine naturwissen
Vorschläge:
Kleine naturwissenschaftliche Bibliothek
Kleine naturwissenschaftliche Bibliothek Reihe Mathematik
Kleine naturwissenschaftliche Bibliothek Reihe Physik
Kleine naturwissenschaftliche Schriften
Um eine Autovervollständigung zu realisieren, gibt es mehrere Ansätze mit entsprechenden Vor- und Nachteilen. (Aufgrund der Komplexität der Thematik wird auf das Mapping und den Indexaufbau in diesem Artikel nicht im Detail eingegangen.) Die ursprüngliche Zeichenkette muss dabei analysiert und beginnend von links nach rechts zerlegt werden (Trennzeichen). Möchte man ein anderes Szenario umsetzen, wobei auch Treffer innerhalb einer Zeichenkette möglich sein sollen, dann muss der Index der Suchmaschine auch entsprechend anders aufgebaut sein.
Folgende Suchbegriffe veranschaulichen die möglichen Treffer für diesen Anwendungsfall: naturwissenschaftliche bibliothek
Eingabe (enthält): naturwissenschaftliche biblio
Vorschläge:
Benzingers Naturwissenschaftliche Bibliothek
Kleine naturwissenschaftliche Bibliothek
Mathematisch-naturwissenschaftliche Bibliothek
Populäre naturwissenschaftliche Bibliothek
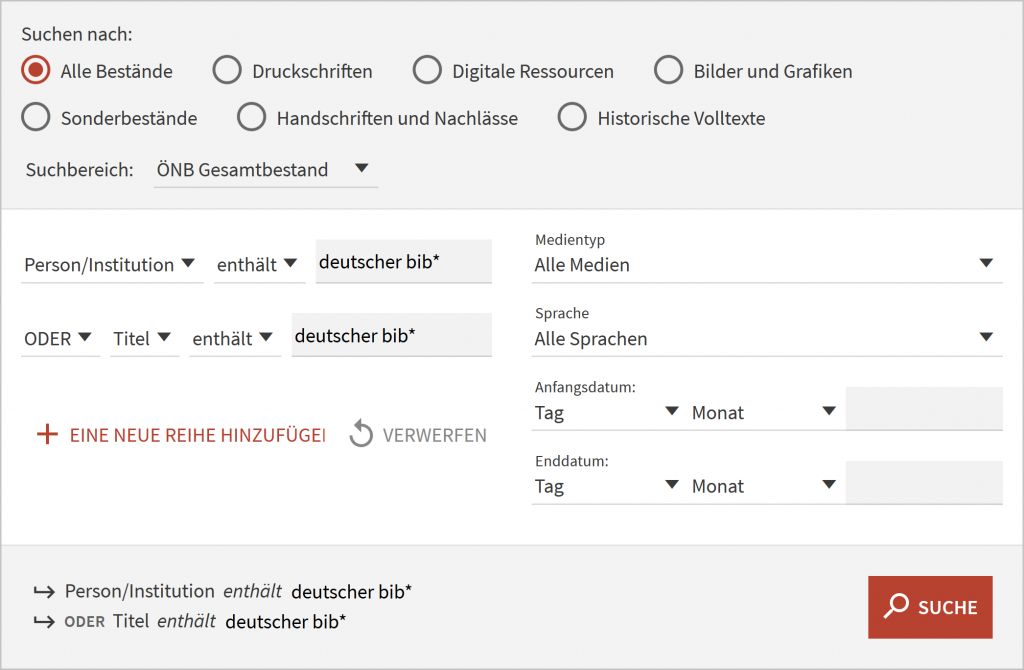
Am Beginn des Indexaufbaues steht jedenfalls immer die Analyse der Zeichenkette im Quelldatensatz. Diese wird schließlich gemäß der Indexparameter in einen invertierten Index übernommen. Dies passiert bereits beim Indizieren (Indextime). Bei der Suche (Searchtime) wird die Eingabe mit dem Index abgeglichen und auf Grundlage des Suchergebnisses kann danach noch eine Aggregation erfolgen. Diese ermöglicht z.B. eine weitere Gliederung und Bezifferung der Treffer per Kategorie. Die Treffer der Autovervollständigung wären allerdings sehr zahlreich. Nur die ersten 10 Treffer (5 bis 20 je nach Performance) würden aufscheinen, wobei die Suchmaschine ein Ranking vornehmen würde. Die Felder, aus denen sich ein Index für die Autovervollständigung zusammensetzen könnte, müssten sehr überlegt gewählt werden.
(Foto: www.onb.ac.at)
Eingabe (enthält): deutscher bib
Vorschläge (z.B.):
Deutscher Bibliothekartag
Die Bibliothek zwischen Autor und Leser: 92. Deutscher Bibliothekartag in Augsburg 2002
Netzwerk Bibliothek: 95. Deutscher Bibliothekartag in Dresden 2006
Verein Deutscher Bibliothekare
Verein Deutscher Bibliothekare Kommission für Einbandfragen
Vorschläge nach Kategorie (z.B.):
Sachtitel (2 Treffer)
Die Bibliothek zwischen Autor und Leser: 92. Deutscher Bibliothekartag in Augsburg 2002
Netzwerk Bibliothek: 95. Deutscher Bibliothekartag in Dresden 2006
Körperschaft (3 Treffer)
Deutscher Bibliothekartag
Verein Deutscher Bibliothekare
Verein Deutscher Bibliothekare Kommission für Einbandfragen
(Foto: www.oeticket.com)
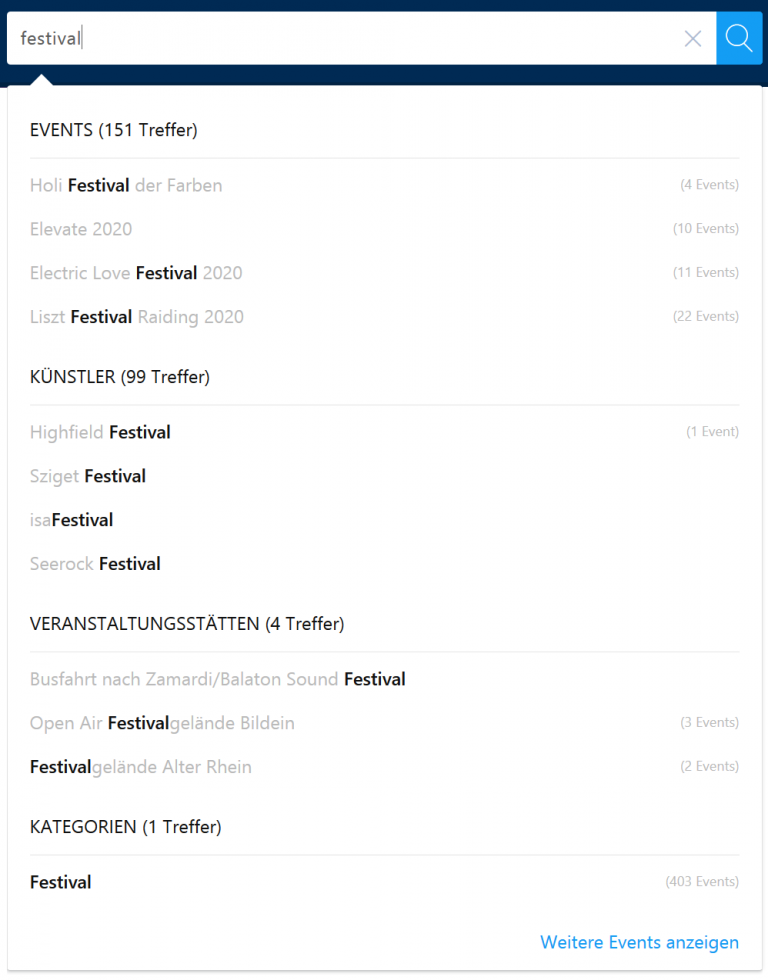
Der theoretische Ansatz einer komplexen Autovervollständigung, wie an dem Beispiel der Website oeticket.com, ist die Verbesserung der Mensch-Maschine-Kommunikation in der Weise, dass die Suchmaschine selbst bekannt gibt, in welchem Zusammenhang sie einen bestimmten Begriff „kennt“ oder welches Muster sie zu diesem „erlernt“ hat. Sie gibt also die Semantik oder vielmehr den Kontext vor, welche auf der inneren Datenstruktur der Dokumente basiert, ohne dem Benutzer das Erfordernis abzuverlangen, sich mit dieser Struktur schon bei der Eingabe beschäftigen zu müssen. So wird vermieden, dass der Benutzer ein Null-Treffer-Ergebnis erhält, wenn er einen Begriff in einer Kategorie eingibt, der dort nicht existiert.
Der Suchbegriff „festival“ ist in den Daten der Suchmaschine in der Kategorie „Events“, „Künstler“, „Veranstaltungsstätten“ und „Kategorien“ enthalten. Das kann ein Benutzer einer Datenbank oder einer Website allerdings nicht erahnen. Wählt der Benutzer nun einen Eintrag aus der Liste aus, wird dem Suchbegriff damit zugleich die korrekte Kategorisierung mitgegeben. Funktional entspricht dies einer Expertensuche. Man erspart sich auf diesem Weg aber das Design einer differenzierten Eingabeoberfläche mit Kategorisierungen und Drop-Down-Menüs oder anderen Elementen zur Eingrenzung der Suche – also ein kompliziertes User-Interface. Ein modernes Usability-Konzept für komplexe Suchen unterstützt den Benutzer so weit wie möglich bei der Eingabe, um keine Suchanfragen zu generieren, die nicht zielführend verlaufen würden: zu viele Treffer, keine Treffer auf Grund von falscher Bedienung oder wegen Tippfehlern, nicht nachvollziehbare Treffer.
Die Bedeutung des User-Interfaces
Es stellt sich die Frage, warum man sich mit der Thematik des User-Interfaces beschäftigen soll, wenn eine moderne Suchmaschine nur noch einen Suchschlitz für alle Benutzereingaben zur Verfügung stellt. Ein einfaches, aber kompaktes Rechercheservice benötigt kein sehr kompliziertes User-Interface, um dem Benutzer alle gewünschten Funktionalitäten bei der Suche zur Verfügung zu stellen. Ähnliches kann auch für Online-Shops oder andere Rechercheportale gelten.

(Foto: www.oeticket.com)

(Foto: www.semanticscholar.org)

(Foto: www.onb.ac.at)
Autovervollständigung zusammen mit weiteren Möglichkeiten der Eingrenzung der Ergebnisse (Drill-Down-Menüs, Drop-Down-Menüs, Schieberegler (UI-Slider) für die Einstellung eines Zahlen- oder Datums-Bereichs) decken den wesentlichen Funktionsumfang der gängigsten Rechercheanforderungen ab.
Visualisierung als Unterstützung bei der Datenselektion
Visualisierungen mit hinterlegten Funktionalitäten zur Einschränkung der Trefferanzahl dienen ebenfalls der Unterstützung in der Handhabung und der Verbesserung der Userexperience. Jede Visualisierungsform wäre denkbar – von 2D bis 3D –, sofern dies zielführend ist und performant umgesetzt werden kann.
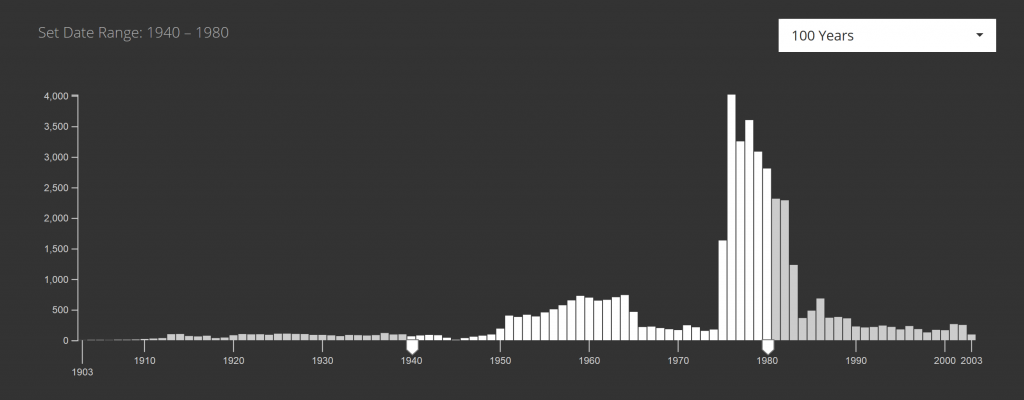
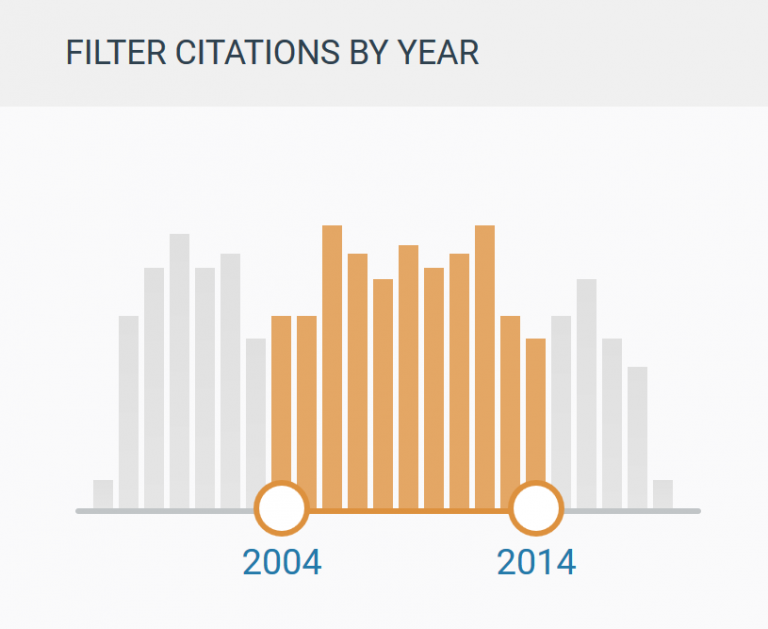
Rechercheportale, die eine Expertensuche anbieten, kommen kaum ohne einen umfassend gestalteten Eingabebereich aus. Die Eingabefelder der erweiterten Suche weisen zahlreiche UI-Elemente und Einstellungsoptionen auf. Das Problem liegt auf der Hand: Ein Eingabefeld kann nur einfachen Text aufnehmen. Für eine differenziertere Eingabe sind nach wie vor mehrere Eingabefelder nötig. Dies gilt als etablierter Design-Standard. Im Kontext von „User-Inferface-Design“ ist auf die Einsatzmöglichkeiten von UI-Tags hinzuweisen.
UI-Tags und erweiterte Objekteigenschaften (Expertensuche)
Tags sind üblicherweise als HTML-Liste gestaltet und man kennt diese aus Web-Blogs, wo sie zur Kategorisierung eines Beitrages genutzt werden. Tags zählen inzwischen auch zu den gängigen Design-Patterns für Websites. Als Komponente zum JavaScript-Framework jQuery gibt es zahlreiche Tagging-Libraries mit unterschiedlichem Funktionsumfang. Tags sind daher häufig im Gebrauch, um Kategorien zu verwalten.
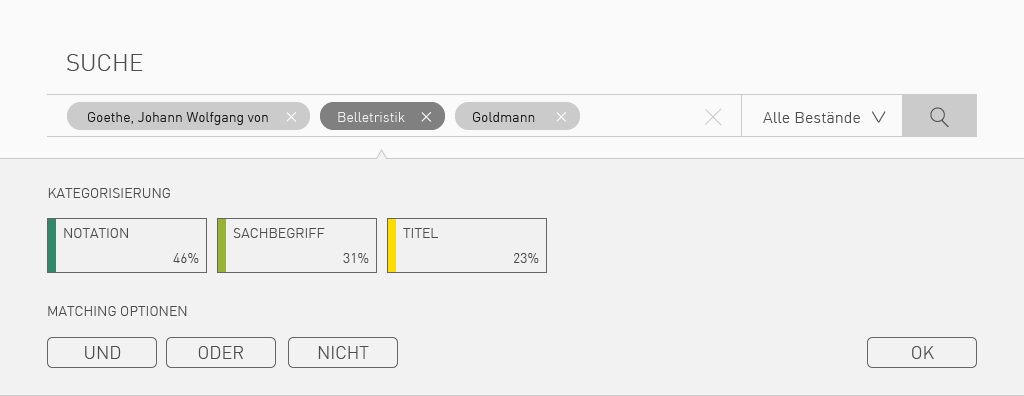
Die Umsetzung von Tag-UI-Elementen ist deshalb bemerkenswert, weil es sich um Objekte (genauer um JavaScript-Objekte) handelt. Damit erhalten UI-Elemente, die gestalterisch als Blockelement formatiert sind, eine programmatische Komponente. Man kann diesen Elementen jeweils eigenständige Eigenschaften zuweisen, die beim Ausführen der Suche ausgelesen werden können. (Siehe dazu: Chips-Elemente in Googles Material-Design) Auf diesem Weg lässt sich eine Syntax realisieren wie sie beispielsweise BASE nutzt.
Beispiel (Syntaxschreibweise von BASE): tit:suchmaschine tit:katalog year:[2015 TO *]
(www.base-search.net/Search/Results?type=all&lookfor=tit:suchmaschine+tit:katalog+year:[2015+TO+*]&ling=0&oaboost=1&name=&thes=&refid=dcresde&newsearch=1)
Beispiel (aufgeschlüsselt als Eigenschaften):
1. Suchbegriff (term): suchmaschine
Boolescher Operator: AND
Type: String
Field: Title
2. Suchbegriff (term): katalog
Boolescher Operator: AND
Type: String
Field: Title
3. Suchbegriff (term): 2015
Boolescher Operator: AND
Type: Year
Field: Year
Range: >= 2015
Die Darstellung in Objektnotation zeigt sich wie folgt (so würden diese Eingabeparameter an die Suchmaschine – z.B. als RESTful Service aufgebaut – weitergeleitet werden):
[
{
"term": "suchmaschine",
"type": "String",
"field": "Title",
"operator": "AND"
},
{
"term": "katalog",
"type": "String",
"field": "Title",
"operator": "AND"
},
{
"term": "2015",
"type": "Year",
"field": " Year ",
"operator": "AND",
"range": {
"gte": 2015
}
}
]
Die Objektrepräsentation wird ausschließlich vom Userinterface verwaltet und stellt damit eine Funktionalität des Frontends dar. Die Suchmaschine als Backend-Applikation erhält alle Suchparameter in der Form, wie es die Schnittstelle erfordert. Der Suchschlitz übernimmt die klassische Funktion der Verarbeitung der Usereingabe. Das Userinterface verwandelt diese gemäß den spezifischen Anforderungen der Applikation in UI-Elemente mit Objekteigenschaften, die durch den Benutzer editierbar sind (z.B. durch Klick wodurch sich ein Kontextmenü öffnet). Ein Klick auf den UI-Tag initiiert beispielsweise ein Dialogfeld, das sich als Ergebnis einer Abfrage an die Suchmaschine öffnet, um die verfügbaren Optionen für exakt diesen Suchparameter anzubieten – gemäß dem weiter oben beschriebenen Konzept des optimalen Mensch-Maschine-Dialogs.
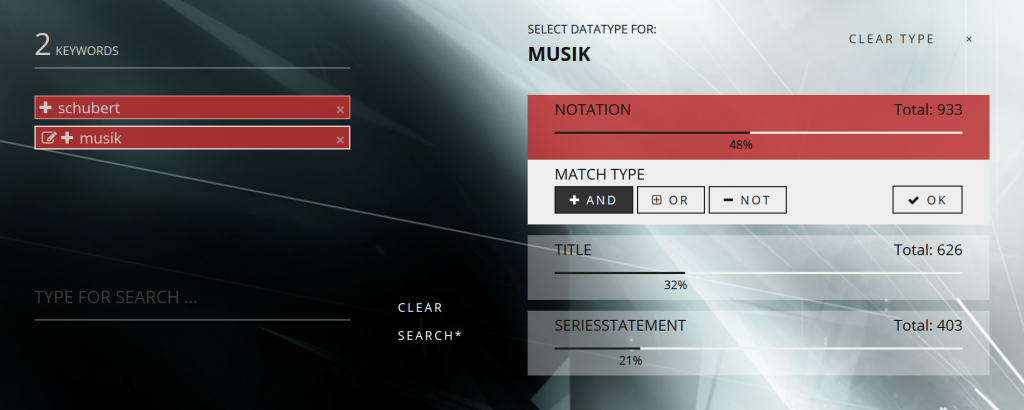
Das Dialogfeld beinhaltet beispielsweise eine prozentuelle Verteilung des Begriffes in den Datenfeldern der Datensammlung und liefert weitere Optionen für die Suche (Boole‘sche Operatoren, Matching-Parameter). Diese Funktionalität kann für einen einzelnen Begriff oder für eine Zeichenkette, bestehend aus mehreren Wörtern (Zitat, Entität), gelten. Die Realisierungsmöglichkeiten sind recht vielfältig. Bedeutend dabei ist lediglich das Design der User-Interaktion (UX). Es bedarf keiner komplexen Eingabeoberfläche. Ein Eingabefeld für alle Benutzereingaben kann ausreichend sein, um die Suchparameter einer erweiterten Suche bereitzustellen – ein Entwurfsmuster, das es noch zu erproben gilt.
Fazit
Für die Recherche wird immer weniger Zeit aufgewendet und deshalb sollte diese möglichst direkt zum gewünschten Dokument führen. Die NutzerInnen erwarten zunehmend, direkt auf die Volltextressource zugreifen zu können. Bevorzugt werden Quellen, die zu einem Volltext führen – ein weiterer Grund warum Suchmaschinen populär geworden sind. Suchmaschinen erfreuen sich großer Beliebtheit, weil sie bequem zu bedienen sind. Die zugrundeliegende Technologie wird durch intelligente Methoden erweitert. Darunter fallen vor allem algorithmische, semantische und statistische Verfahren. Weiters zählen dazu noch Verfahren auf dem Gebiet der künstlichen Intelligenz (KI) und der neuronalen Netze. Bei Ausgangsbedingungen, wie vernetzte Informationsstrukturen und Heterogenität der Datenquellen bietet die Suchmaschine viele Vorteile, was das assoziative Auffinden von Informationen betrifft.
Die Usability-Standards haben sich seit der Einführung der Suchmaschine in der Webrecherche verändert und werden laufend weiterentwickelt. Obwohl mit der Einfachheit der Bedienung auch Kompetenzen an die Maschine ausgelagert werden, hat sich die Technologie durchgesetzt und gilt als etabliert und akzeptiert. Um der Expertensuche zu noch größerer Popularität zu verhelfen, könnte die Einführung neuer Designpatterns hilfreich sein. Die Zielsetzung dieser Designpatterns wäre, Komplexität zu reduzieren, und gleichzeitig die Interaktion mit der Maschine intuitiver sowie kommunikativer zu gestalten.
Dieser Artikel beinhaltet einen Auszug des 2020 veröffentlichten Beitrages in der Zeitschrift ABI Technik:
Weiner, J. (2020). Vom Katalog zur Suchmaschine, ABI Technik, 40(1), 60-72.
doi: https://doi.org/10.1515/abitech-2020-1007



